JavaScript Editor
JavaScript Debugger
JavaScript Editor
JavaScript Debugger
Before you dive into a full-fledged peer-to-peer application, you need to understand some of the design issues that affect every peer-to-peer project. These are questions about peer identity, discovery, communication, and interaction. In this chapter, you'll investigate these issues and dissect different types of peer-to-peer architecture.
You'll notice that this is a fairly short chapter. There's a reason for that. Although peer-to-peer architecture is important, it's often more helpful to see live examples than volumes of theory. This chapter is only meant to introduce the basics that you need to understand the peer-to-peer examples developed throughout the book.
One characteristic you won't find in the peer-to-peer world is consistency. The more you learn about different peer-to-peer applications, the more you'll see the same problems solved in different ways. This is typical of any relatively new programming model in which different ideas and techniques will compete in the field. In the future, peer-to-peer applications will probably settle on more common approaches. But even today, most of these techniques incorporate a few core ingredients, which are discussed in the following sections.
In a peer-to-peer system, a peer's identity is separated into two pieces: a unique identifier, and a set of information specifying how to contact the peer. This separation is important—it allows users in a chat application to communicate based on user names, not IP addresses, and it allows peers to be tracked for a long period of time, even as their connection information changes.
The connectivity information that you need depends on the way you are connecting with the peer, although it typically includes information such as a port number and IP address. (We'll examine this information in detail in Chapter 7, which explains core networking concepts.) The peer ID is a little trickier. How can you guarantee that each peer's identifier is unique on a large network that changes frequently?
There are actually two answers. One approach is to create a central component that stores a master list of user information. This is the model that chat applications such as Windows Messenger use. In this case, the central database needs to store authentication information as well, in order to ensure that peers are who they claim to be. It's an effective compromise, but a departure from pure peer-to-peer programming.
A more flexible approach is to let the application create a peer identifier dynamically. The best choice is to use a globally unique identifier (GUID). GUIDs are 128-bit integers that are represented in hexadecimal notation (for example, 382c74c3-721d-4f34-80e5-57657b6cbc27). The range of GUID values is such that a dynamically generated GUID is statistically unique—in other words, the chance of two randomly generated GUIDs having the same value is so astonishingly small that it can be ignored entirely.
In .NET, you can create GUIDs using the System.Guid structure. A peer can be associated with a new GUID every time it joins the network, or a GUID value can be generated once and stored on the peer's local hard drive if you need a more permanent identity. Best of all, GUIDs aren't limited to identifying peers. They can also track tasks in a distributed-computing application (such as the one in Chapter 6) or files in a file-sharing application (as shown in Chapter 9). GUIDs can also be used to uniquely identify messages as they are routed around a decentralized peer-to-peer network, thereby ensuring that duplicate copies of the same message are ignored.
Regardless of the approach you take, creating a peer-to-peer application involves creating a virtual namespace that maps peers to some type of peer identifier. Before you begin to code, you need to determine the type of peer identifier and the required peer connection information.
Another challenge in peer-to-peer programming is determining how peers find each other on a network. Because the community of peers always changes, joining the network is not as straightforward as connecting to a well-known server to launch a client-server application.
The most common method of peer discovery in .NET applications is to use a central discovery server, which will provide a list of peers that are currently online. In order for this approach to work, peers must contact the discovery server regularly and update their connectivity information. If no communication is received from a peer within a set amount of time, the peer is considered to be no longer active, and the peer record is removed from the server.
When a peer wants to communicate with another peer, it first contacts the discovery server to learn about other active peers. It might ask for a list of nearby peers, or supply a peer identifier and request the corresponding connectivity information it needs to connect to the peer. The peer-to-peer examples presented in the second and third part of this book all use some form of centralized server.
The discovery-server approach is the easiest way to quickly implement are liable peer-to-peer network, but it isn't suitable for all scenarios. In some cases, there is no fixed server or group of servers that can play the discovery role. In this case, peers need to use another form of discovery. Some options include
Sending a network broadcast message to find any nearby peers. This technique is limited because broadcast messages cannot cross routers from one network to another.
Sending a multicast broadcast message to find nearby peers. This technique can cross networks, but it only works if the network supports multicasting.
Reading a list of super-peers from some location (typically a text file or a web page), and trying to contact them directly. This requires a fixed location to post the peer information.
The last approach is not perfect, but it's the one most commonly used in decentralized peer-to-peer applications such as Gnutella. You'll learn about broadcasting in Chapter 9.
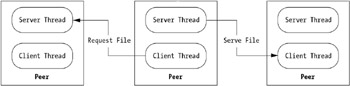
Peer to peer applications often play two roles, and act both as a client and server. For example, in a file-sharing application every interaction is really a client-server interaction in which a client requests a file and a server provides it. The difference with peer-to-peer applications is every peer can play both roles, usually with the help of threading code that performs each task simultaneously. This is known as the server-mode/client-mode (SM/CM) model, as shown in Figure 2-1.
The dual roles in a file-sharing application are fairly obvious, but there are some types of applications that require more server work. For example, in a distributed-computing application, a work manager typically divides a task into multiple task segments, assigns it to a group of workers, and assembles their responses into a final solution. In some respects, this kind of application doesn't appear to be a true peer-to-peer application at all, because it centralizes functionality in a dedicated server module. However, you can make this application into more of a peer-to-peer solution by applying the SM/CM model. For example, you might create a peer that has the ability to request work and perform work for other requesters, as you will in our example in Chapter 6.
Remember, in a single interaction, the parts of a peer-to-peer system are not equivalent. One peer will take the role of a server, while the other acts as a client. However, over a longer time frame, each peer has the capability to play different roles.
Firewalls and network address translation (NAT) devices are the bane of all peer-to-peer applications and can make it all but impossible for peers to interact.
Firewalls act as gatekeepers separating the public Internet and an internal network (or individual computer). Firewalls typically work as a kind of one-way gate, allowing outgoing traffic, but preventing arbitrary outside computers from sending information to a computer inside the Internet. In some cases, firewalls can be configured to allow or deny connections on specific ports, thereby authorizing some channels for peer-to-peer communication, although it's becoming increasingly common for firewalls to lock down almost everything. Further complicating life is NAT, which hides a client's IP address so it's not publicly accessible. The NAT is intelligent enough to be able to route a response from a server to the original client, but other peers can't communicate with the hidden computer. Thus, a peer could work in client-mode, but not server-mode, which would cripple the functionality of the system.
The peer-to-peer working group (http://peer-to-peerwg.org) identifies some of the most common approaches for interacting over a firewall or NAT. Two basic techniques include
Reversing the connection. If PeerA can't contact PeerB due to a firewall, have PeerA contact PeerC, which will then notify PeerB. PeerB can then initiate the connection to PeerA. This won't work if both PeerA and PeerB are behind firewalls.
Using a relay peer. If PeerA and PeerB need to communicate but are separated by a firewall, have them route all communication through some PeerC that is visible to both. JXTA and Gnutella use variations of this approach.
Coding this sort of low-level networking logic is a chore at best. If you need to create peer-to-peer applications over a wide network that can tunnel through firewalls, your best choice may be a third-party tool such as the ones we'll explore in Part Four of this book. Or, you may want to incorporate some centralized components. For example, a typical chat application such as Windows Messenger avoids firewall problems because all clients connect directly to the server, rather than to each other. However, some features (for example, file transfer) use direct connections and are consequently not supported by all peers. You may want to take this approach in your own applications to guarantee basic functionality, while giving peers the option of using direct connections for some features whenever possible.
| Tip |
You can often tell whether the current computer is behind a NAT by examining its IP address. RFC 1918 spells out common NAT addresses: 10.0.0.0–10.255.255.255, 172.16.0.0–172.31.255.255,192.168.0.0–192.168.255.255. If your IP address falls within one of these ranges, you'll be able to create outgoing connections, but won't be able to accept incoming ones. |
Free JavaScript Editor
JavaScript Editor